Horus 1.0 4B
Text Generation Model
A compact yet powerful language model designed for efficient text generation and chat. Horus 1.0 4B delivers strong performance in reasoning and chat tasks.
Architecture
LLaMA-based architecture with proven attention mechanisms
Context
8K tokens context length for efficient text generation
Chat
Optimized for conversational AI and interactive chat
Reasoning
Strong reasoning and logical inference capabilities
Model Versions
Full Weights
Compressed (GGUF)
Detailed Specifications
| Format | File Size | Min RAM | Min VRAM | Quality | Best For |
|---|---|---|---|---|---|
| F16 | 9.03 GB | 12 GB | 10 GB | Maximum quality | High-end GPUs (RTX 3090, A100) |
| Q8_0 | 4.8 GB | 6 GB | 5 GB | Near-lossless | RTX 3060 12GB, RTX 4060 |
| Q6_K | 3.71 GB | 5 GB | 4 GB | Excellent | RTX 3060, RTX 4060 Laptop |
| Q5_K_M | 3.23 GB | 4 GB | 3.5 GB | Very Good | GTX 1650, RTX 3050 |
| Q4_K_M | 2.78 GB | 3.5 GB | 3 GB | Good | Entry-level GPUs, CPU-only |
Model Configurator
Customize your setup and get a ready-to-run code snippet
Select Quantized Version
Your Generated Code
import neuralnode as nn
# Load the Horus 1.0 4B model
horus = nn.load("tokenai/Horus_1.0_4B_GGUF/Horus_1.0_4B_Q4_K_M.gguf")
# Generate text
response = horus.generate("Explain quantum computing in simple terms")
print(response.content)4 Billion parameters compact transformer optimized for efficient local deployment.
LLaMA-based Architecture with proven attention mechanisms for reliable performance.
8K tokens context length suitable for most text generation and coding tasks.
Excels in reasoning and chat tasks while maintaining minimal resource requirements.
Open license enabling unrestricted use and fine-tuning for custom applications.
Performance Benchmarks
| Benchmark | Metric | Horus 1.0 4B | Comparison |
|---|---|---|---|
| MMLU | 5-shot | 71.5 | Phi-3 mini: 68.5 |
| HumanEval | Pass@1 | 65.2 | Phi-3 mini: 62.8 |
| GSM8K | Math | 72.8 | Phi-3 mini: 70.5 |
| BBH | Reasoning | 68.4 | Phi-3 mini: 65.2 |
Standardized Verification
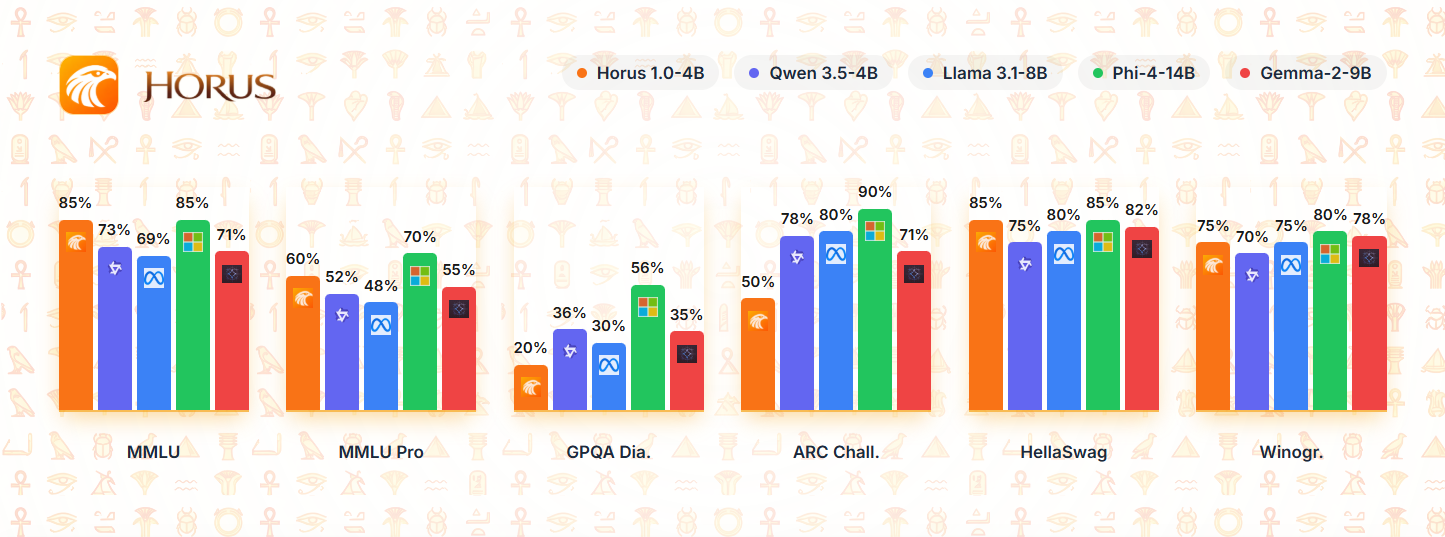
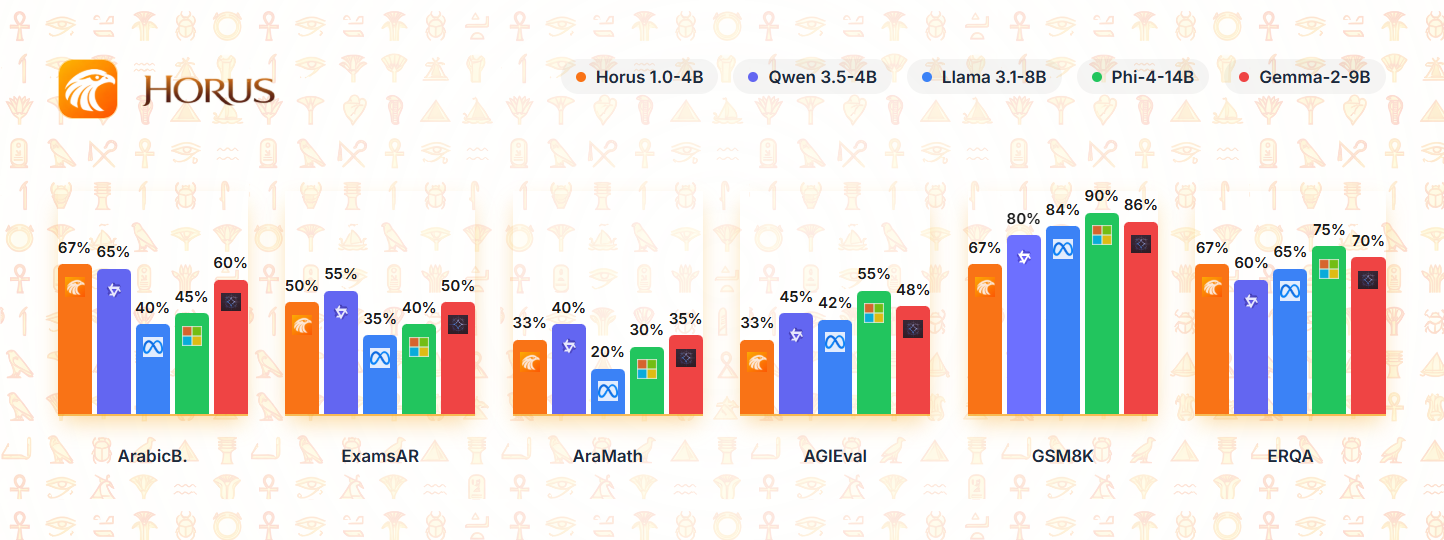
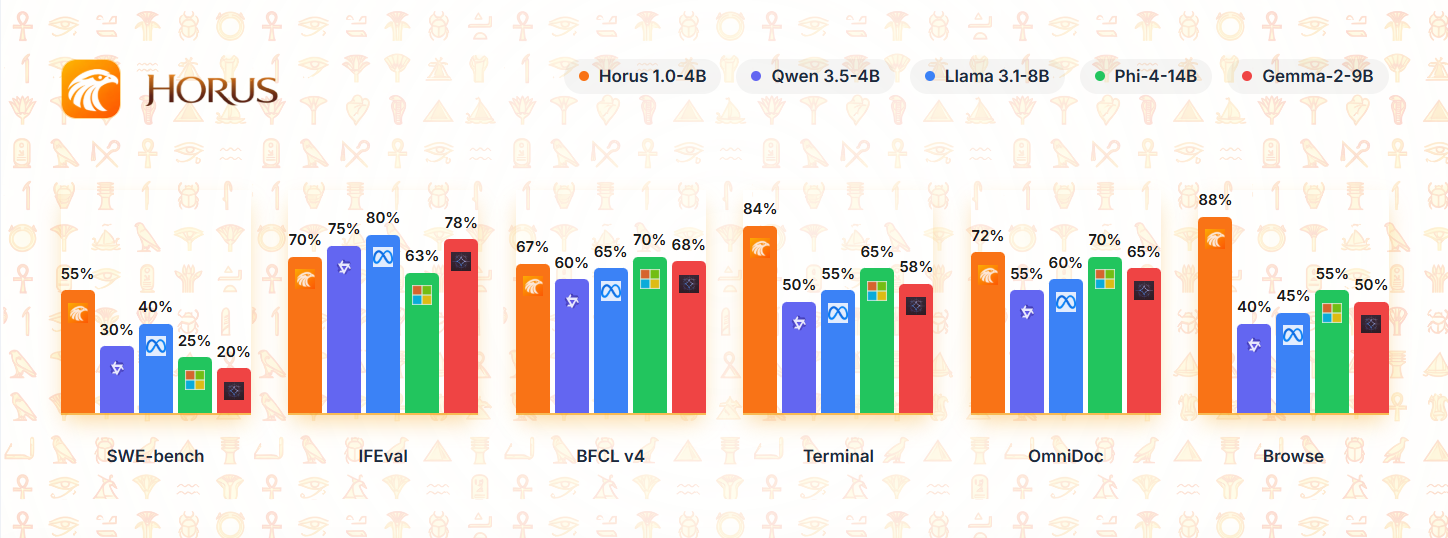
Horus 1.0 4B delivers exceptional performance for its size, making it ideal for developers seeking powerful language capabilities without requiring massive computational resources.